Project Overview & Context
The business is launching a brand-new IR product called "Incident 360 Retainers". The legacy platform must now evolve to accommodate self-service features for these premium contractual benefits.
My Role and Responsibilities
As the Lead Product Designer on this project, I owned the end-to-end user experience of the new dashboard from initial technical discovery and user research through to high-fidelity designs. Working within a compressed 3-month timeline, my core responsibility was to translate a complex new enterprise product offering into a clear, intuitive, and production-ready customer facing interface.
Three compounding failures in the legacy dashboard
The legacy IR Dashboard bare-bones, no visual hierarchy, no self-serve functionality.
Hypothesis
I framed our core design challenge around three distinct pillars:
Project Goals
The Constraint: A 3-Month Timeline
"We had less than one quarter (~3 months) to go from research and testing to development, and post-launch QA."
Since the timeline was incredibly tight, I couldn't design in a vacuum. To fully understand the technical landscape, data-tracking requirements, and what actually needed to surface on the dashboard vs. what was feasible to surface, I interviewed and collaborated directly with technical Subject Matter Experts (SMEs), Customer Success Managers (CSMs), and product partners.
The direct result of this data-gathering research was a comprehensive System User Flow, which helped align UX, Product, and Development by allowing us to stress-test the feasibility of requirements, such as submitting a breach threat and requesting a touchpoint review.
Visual map of the current and future states used to validate how emergency and touchpoint requests would be processed across different retainer tiers.
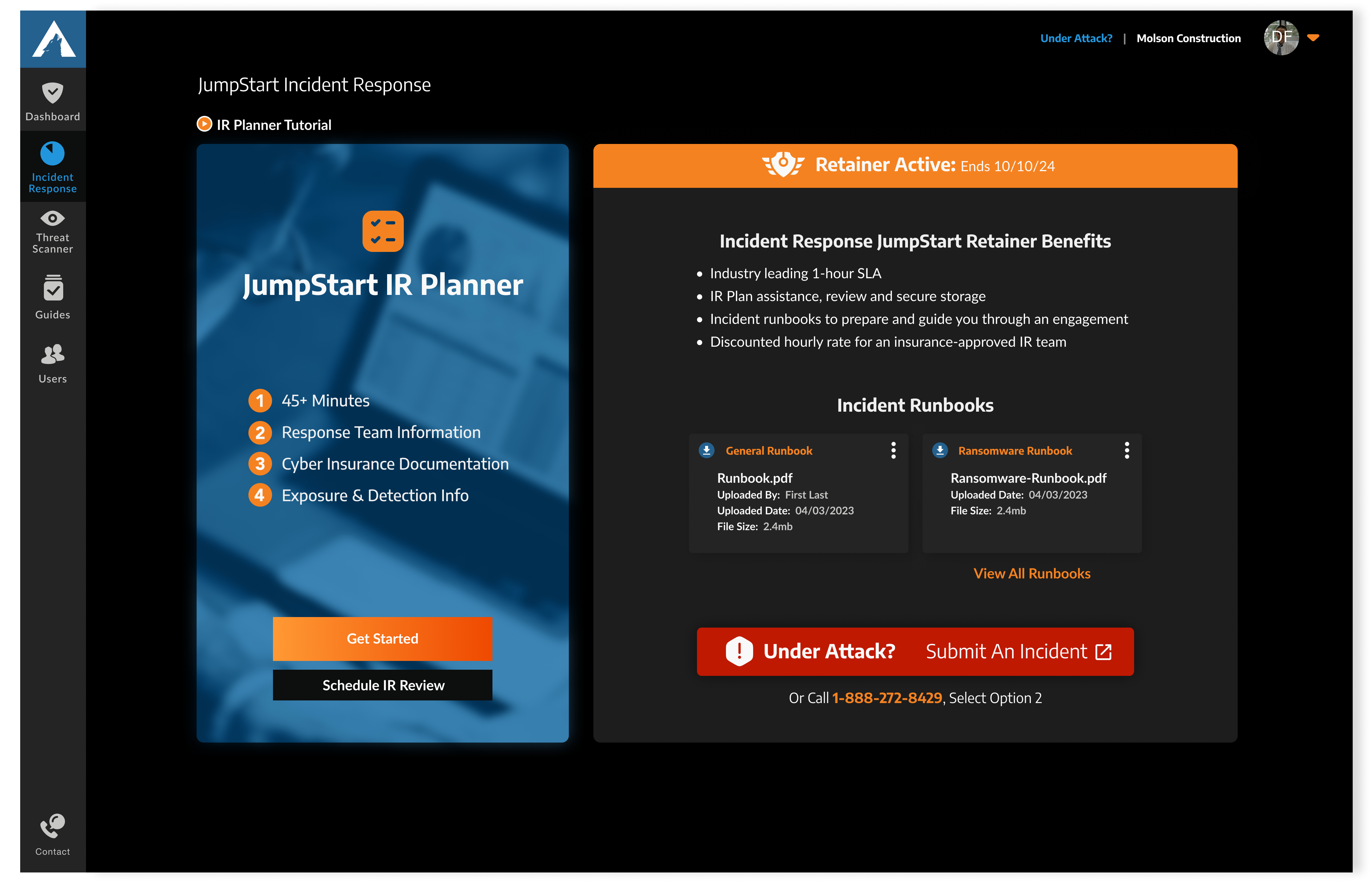
Survey Results: Low IR Plan Completion
When reviewing past research, I uncovered a key insight tied to one of the project goals: encouraging customers to complete their IR Plans.
Survey data showed that the legacy IR Planner had only a 47% completion rate among respondents (IR customers), with many not having started their plans at all.
This pointed to a clear gap. An audit of the legacy dashboard revealed that it didn't clearly communicate the state of the IR Plan specifically whether it had been started or not making it harder for customers to know when to take action.
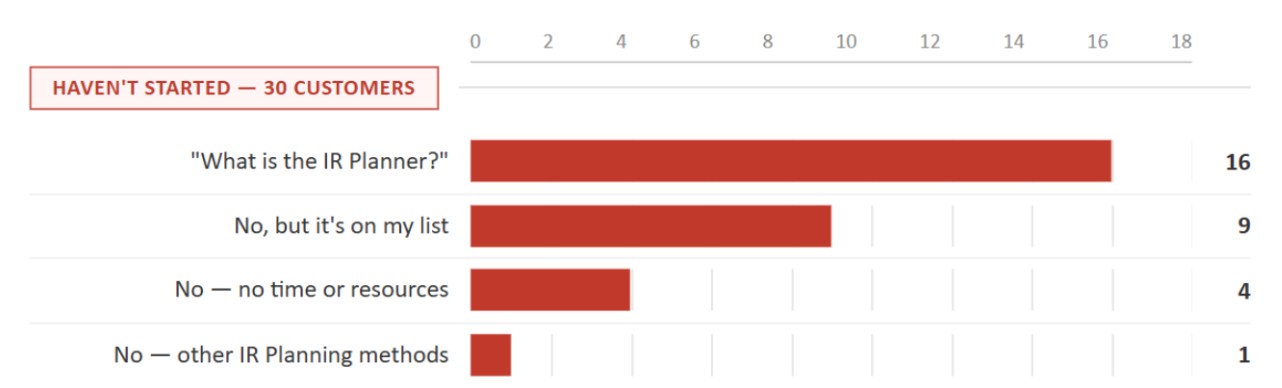
With 53% of customers not yet using the IR Planner, there's an opportunity to improve adoption by making it easier for customers to start using it and understand its value.
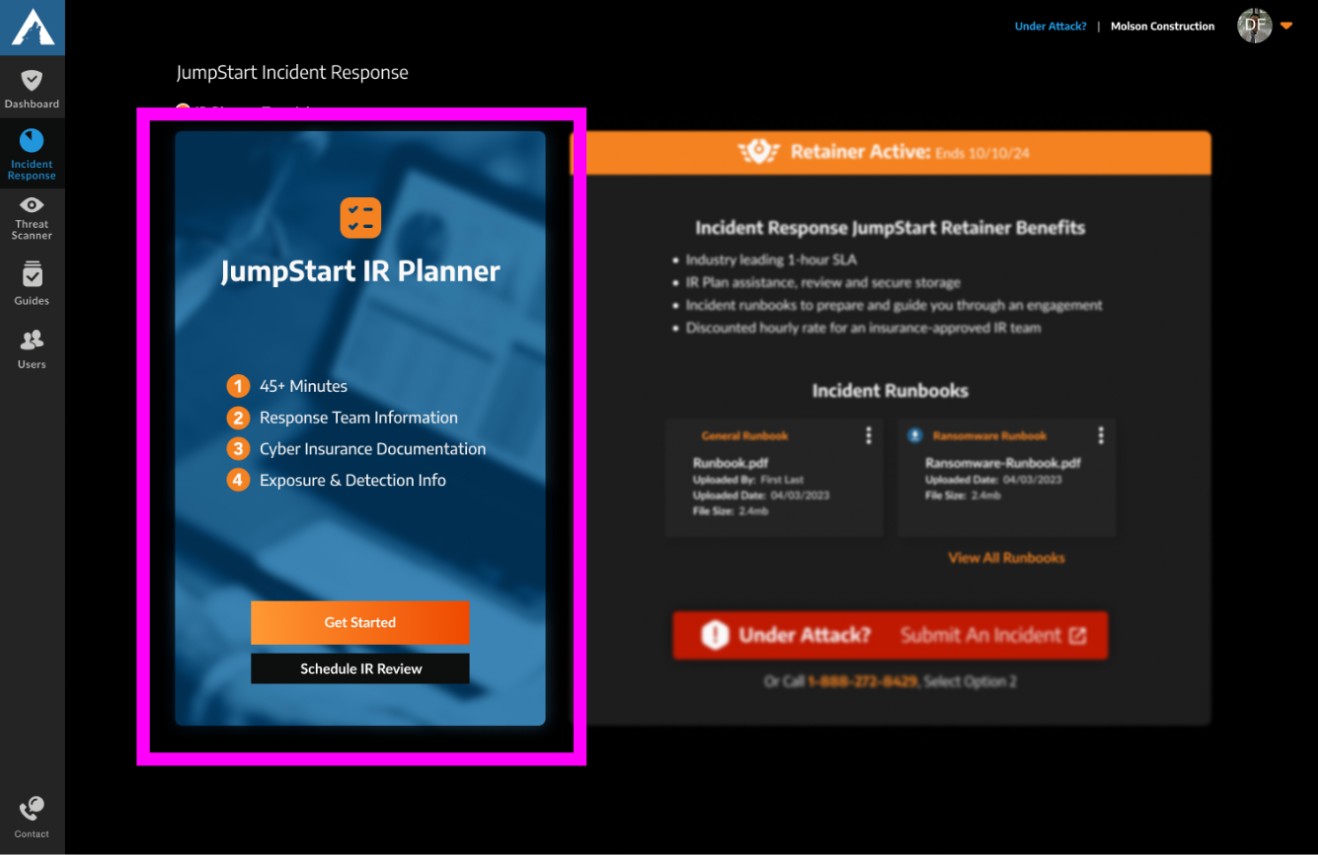
The pink outline highlights the old JumpStart IR Planner widget, which served as the primary call-to-action (CTA) for the legacy IR Dashboard.
Dashboard Layout Explorations
Before diving into individual widget designs, I stepped back to explore different layout directions. My main priority was figuring out how the information should be grouped and structured to make the dashboard as intuitive as possible, so I tested three distinct concepts to see what worked best.
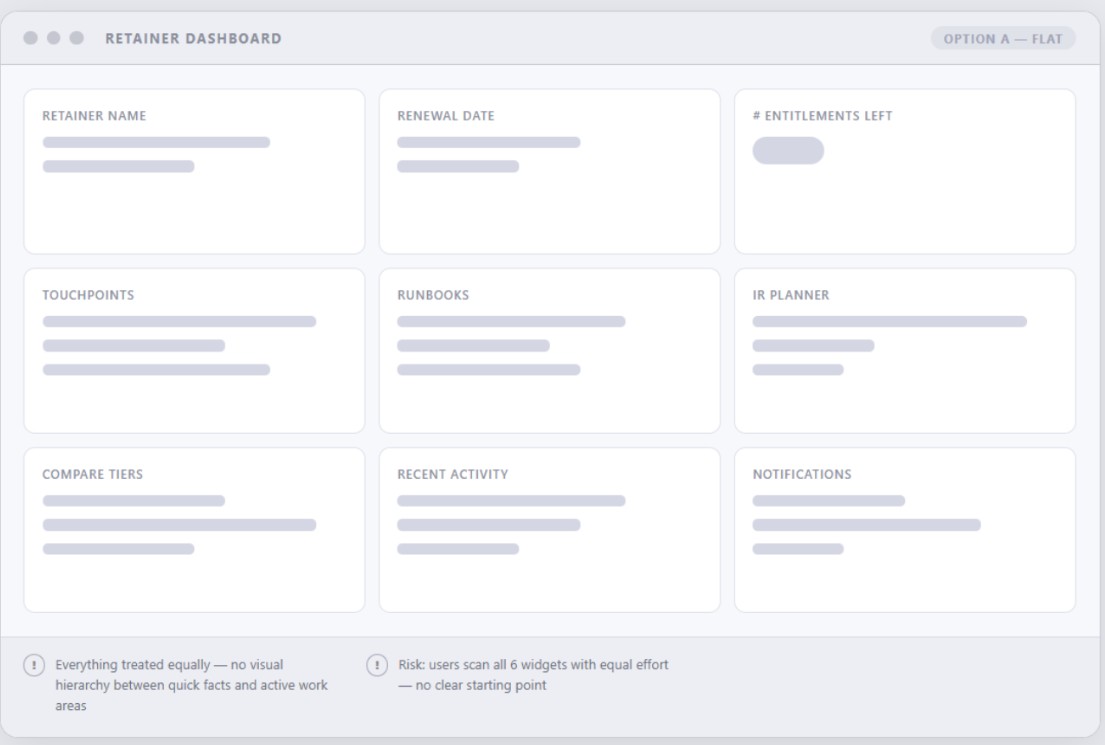
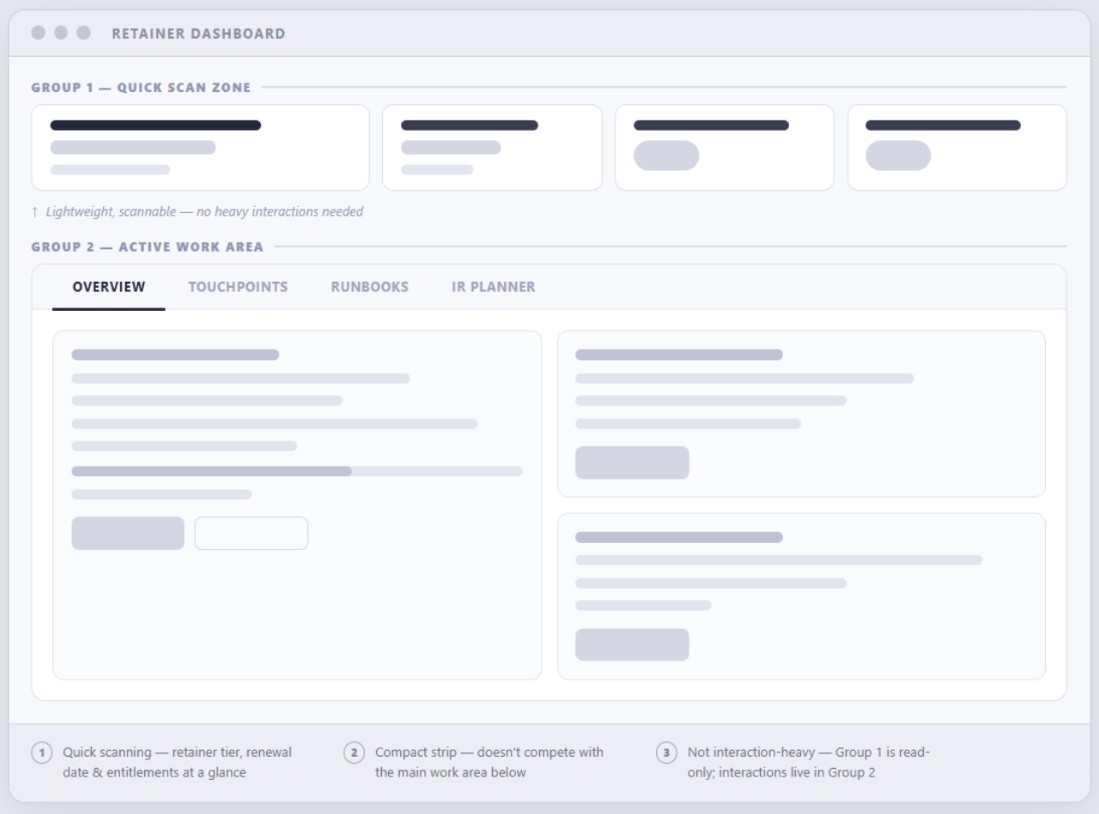
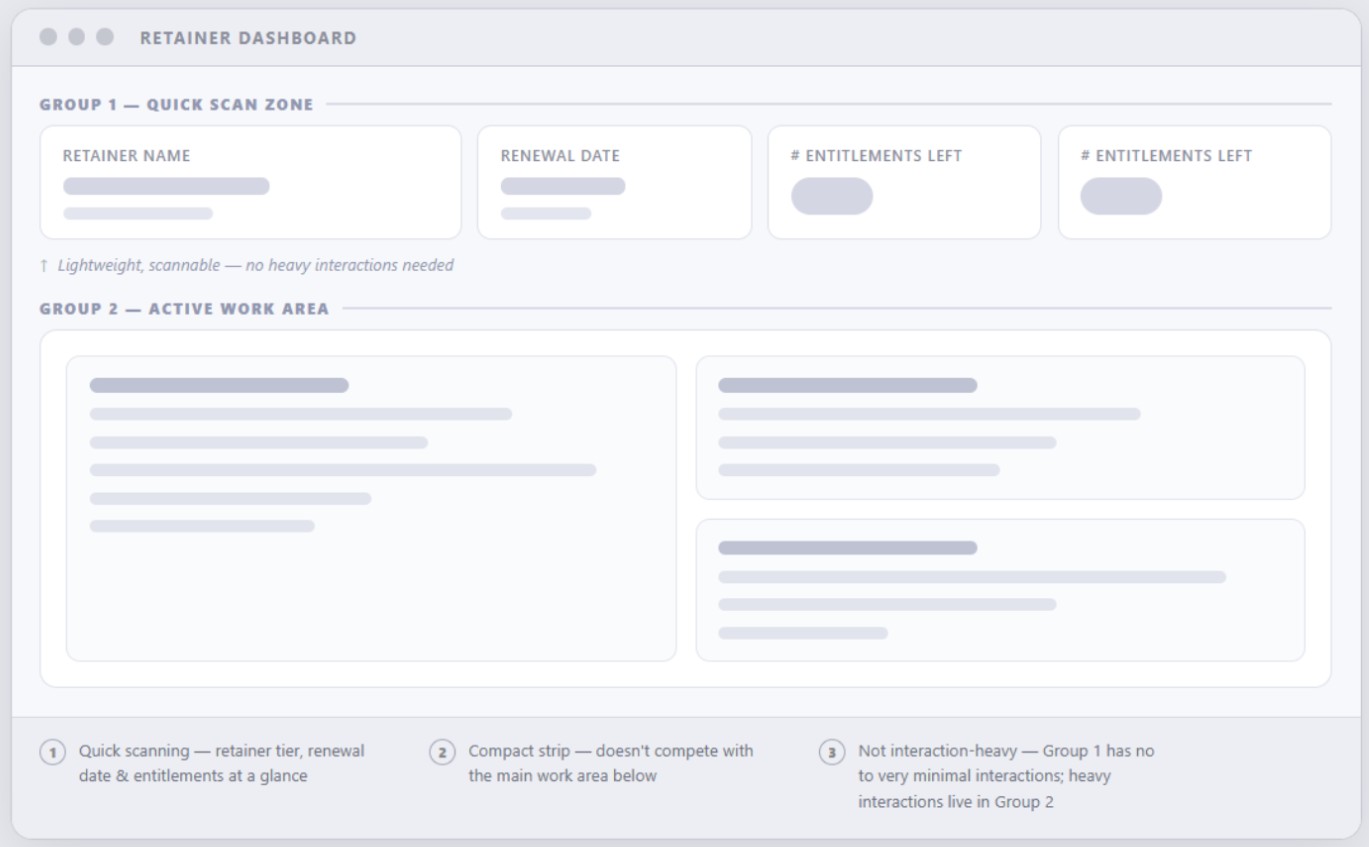
Dashboard Architecture and Layout Strategy
Feedback from Customer Success Managers, Product, and customers made it clear the dashboard needed a more intentional structure. Exploration 3: Overview + Work Area Layout was the only approach that delivered the clarity we needed.
This layout worked best because it naturally grouped information into two key areas:
Quick, factual information
Users frequently log in just to do a fast validation check of what they purchased. Within seconds of logging in, they need to answer a quick mental checklist:
- · What retainer tier have I purchased?
- · When does my retainer expire or renew?
- · How many entitlements do I have available right now?
This resulted in a compact, scannable header section. The retainer content is lightweight, highly scannable, and intentionally designed to avoid complex interactions. It functions purely as a quick check/reminder zone, clearly displaying the retainer name, number of available readiness touchpoints, available covered cases, and their respective renewal dates.
Group 1 top row retainer name, available touchpoints, covered incidents, and renewal dates at a glance.
High-interaction, Active Work Area
This is the meat of the dashboard. It takes up the bulk of the screen real estate because it's where customers engage with self-serve elements to request touchpoints, manage their account, and track readiness activities. This includes tasks like downloading runbooks, comparing retainer tiers, and tracking IR Planner progress. Because these actions are more interactive, they are grouped into an action-focused area of the dashboard.
.png)
The outcome of the two groups coming together.
Core Widget Design: From Architecture to Action
With the macro-level architecture locked into the Overview + Work Area layout, the next challenge was designing the specific components that would populate these zones. I needed to translate our three core "How Might We" goals into tangible UI elements, focusing on three critical widgets placed strategically within the established layout zones:
Top Row
Emergency Widget
Active Work Area
IR Planner Widget
Active Work Area
Touchpoint Widget
Component Deep Dive: The IR Planner Widget
The Problem & User Need
The IR Planner is critical for ensuring customers are prepared for a security incident, but engagement suffers from user inertia. We identified two core user needs to fix this:
- 1.Amplify the Planner State (Started vs. Not Started): If a customer hadn't started their planner, they needed an unmissable call to action. Driving this initial momentum is vital; customers who complete their IR Planner achieve better overall security readiness.
- 2.Encourage Completion: For users who had started, they needed a fast, visual way to track progress so they wouldn't stall out mid-way through the process.
The Design Decisions & Iteration
Unstarted State: To solve the discovery problem, I designed a dedicated, high-contrast unstarted state featuring a single, prominent "START" CTA button that immediately routes users directly into the onboarding flow.
Started State (V1 vs. V2): Once the planner is underway, the widget transforms into a progress tracker.
V1 (The Sub-Section Approach): In the first iteration, the widget attempted to surface granular sub-sections (e.g., breaking down the 'Response' section into Legal, Technical, and Financial Leaders).

V1 Granular sub-section breakdown
Why V1 was cut
Too much visual clutter granular sub-sections overwhelm a confined dashboard widget
Sub-sections aren't universally applicable business sizes vary too much to generalize at widget level

V2 Simplified progress bars
The final V2 widget strips away the clutter and focuses purely on high-level progress. It clearly displays the core sections of the IR Planner alongside simplified progress bars showing exactly how much of each section has been completed. This delivers a quick, lightweight understanding of readiness activity without overwhelming the user or making false assumptions about their organizational incident readiness.
Component Deep Dive: The Touchpoint Self-Serve Widget
The Problem & User Need
To improve their security posture, customers need to engage in expert-led sessions with cybersecurity professionals. However, because this was a brand-new product offering, we needed to build the booking process from the ground up. We identified three critical needs to address:
- 1.Decision Support: Customers needed a way to easily evaluate the three available touchpoint types and decide which one to utilize next.
- 2.Strict Self-Serve Requirement: From a business perspective, relying on manual "support ticket" submissions to book these sessions was completely off the table it simply wouldn't scale. We had to design an intuitive self-serve mechanism from day one to prevent a massive surge in administrative overhead.
- 3.End-to-End Lifecycle Tracking: Users needed visibility into past interactions such as viewing notes, documents, and feedback from previously completed touchpoints.
The Design Decisions & Component Anatomy
To create an intuitive, self-contained scheduling experience within the main dashboard, I structured the widget around three key UI elements:
Since there are three distinct touchpoint types defined by the product, I used a tabbed layout at the top of the widget. This allows users to focus on one touchpoint at a time in its own dedicated space without feeling overwhelmed.
Selecting a tab dynamically updates the widget's body text with the touchpoint name and a concise description. This immediately gives users "the gist" of what the session covers, proactively eliminating the ambiguity that would otherwise drive a surge in support inquiries.
Primary: "Request Touchpoint" a high-contrast button that kicks off the connection process, validates entitlement intent, and transitions the user into the delivery stage.
Secondary: "View Touchpoints" a lower-emphasis button giving customers quick access to historical data and artifacts from past completed sessions.
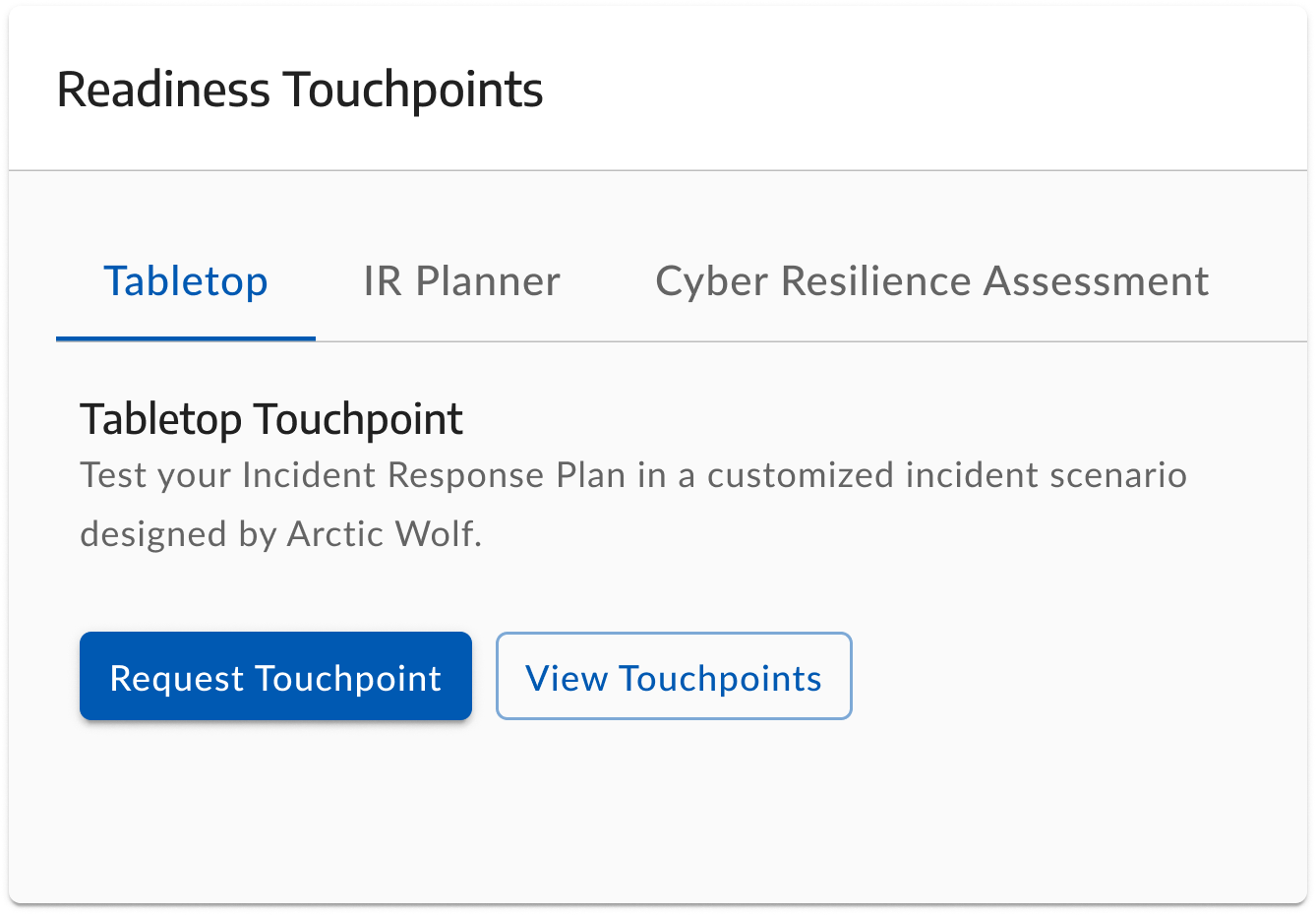
Final Touchpoint widget tabbed architecture with contextual descriptions and a clear request/view action hierarchy.
The final Touchpoint widget successfully establishes a scalable, lightweight self-serve feature right out of the gate. By pairing educational context with a strict action hierarchy, we preemptively bypassed the need for support-ticket middle-men, launching an intuitive system that empowers customers to independently manage their security engagements throughout their retainer term.
Component Deep Dive: The Emergency "Report a Breach" Widget
The Problem & User Need
When a customer is experiencing an active cyber attack, they are in a high-stress, high-panic state. In that exact moment, they need a literal PANIC, emergency button.
- 1.Instant Discoverability: The action had to be radically clear and effortlessly easy to find within seconds of logging in. There is zero room for cognitive load or searching through menus.
- 2.Immediate Direction: Users needed to know exactly where to look and precisely what to do the moment a crisis hit.
The Design Decisions & Spatial Layout Constraint
Once the rest of the dashboard widgets found their homes, I had to balance a unique paradox: The emergency button needs to demand critical attention when necessary, but it shouldn't dominate everyday screen real estate since it represents a rare, worst-case scenario.
To achieve this, I made four highly intentional spatial and visual choices:
- 1.Strategic Placement (Top-Row Architecture): I placed the widget in the Group 1 top header row. Eye-tracking patterns show that customers look at the top-left and top-right of a dashboard first upon loading.
- 2.Purposeful Visual Segregation: By right-aligning the emergency button, I purposefully distanced it from the passive retainer data. This ensures the widget stands out as a distinct, high-priority action rather than blending in with routine account stats.
- 3.High-Contrast Color Psychology: I made the widget deep red to immediately draw critical attention. This instantly flags emergency priority, matching the user's urgent mental state, and acts as a universal visual anchor on a dark/neutral interface.
- 4.Designing for the "Once in a Blue Moon" Edge Case: Instead of making the element larger, I relied on stark color contrast and strategic placement to do the heavy lifting perfectly preserving the balance of the everyday workspace.
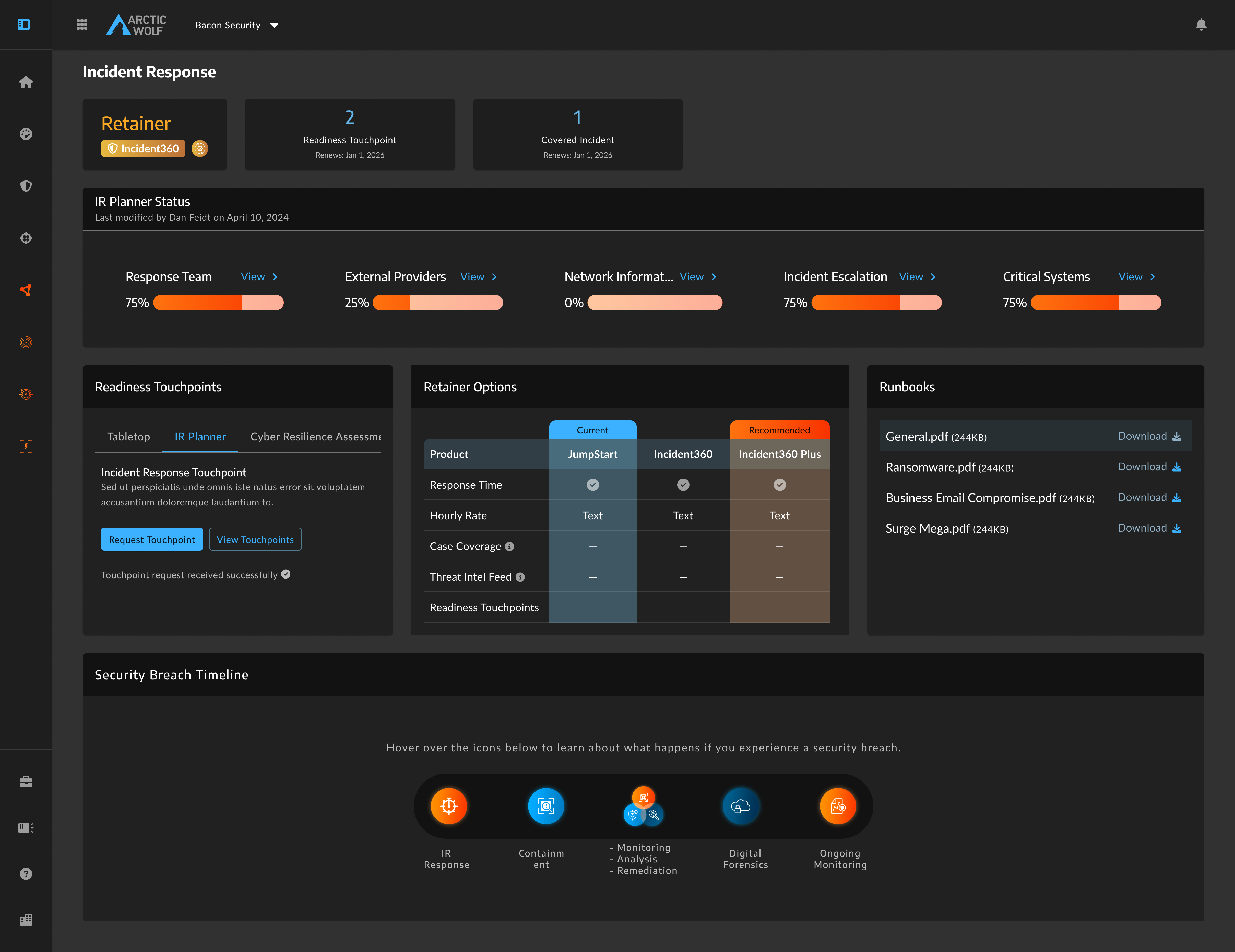
Dashboard before no emergency entry point. A user under attack would have nowhere obvious to turn.
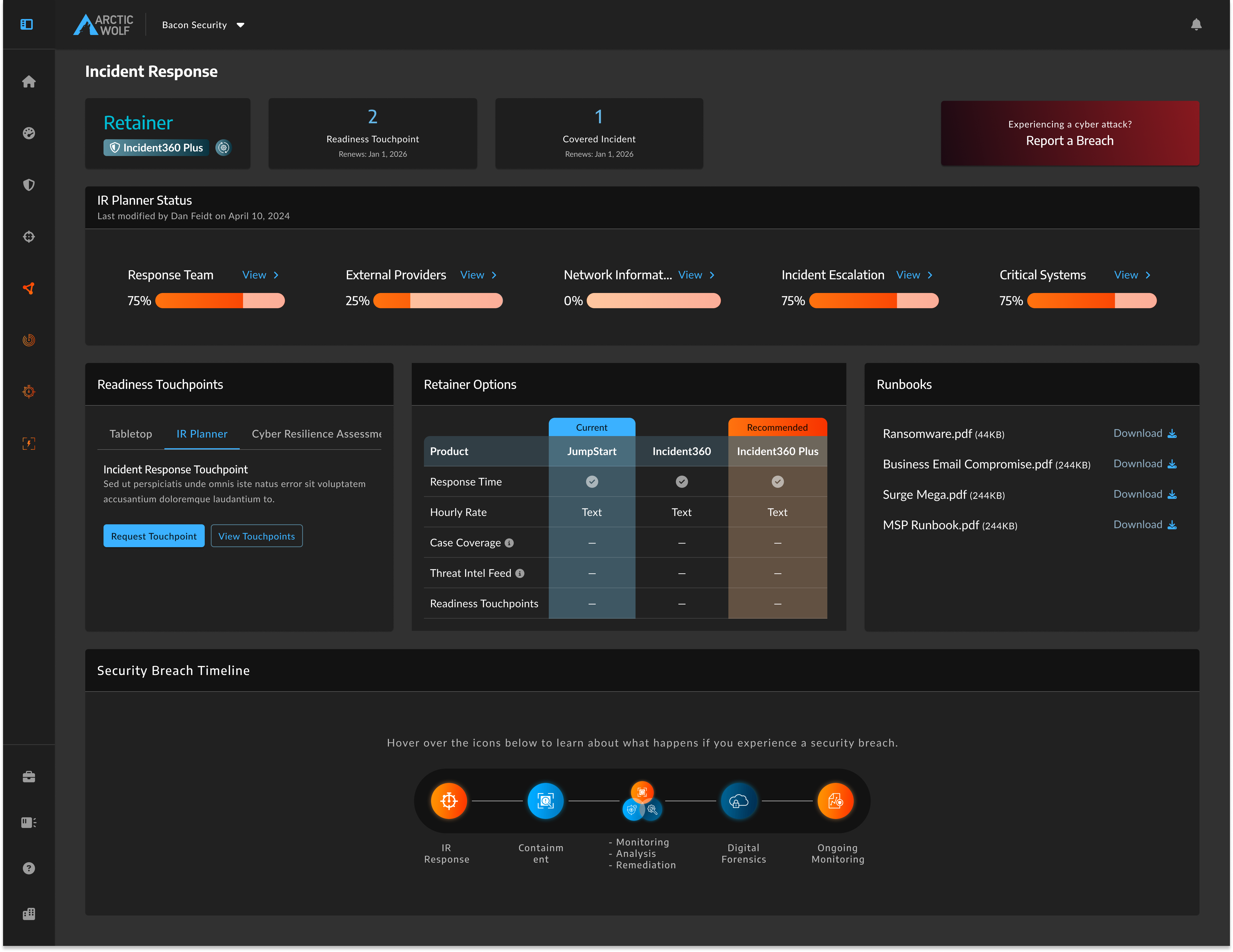
After the 'Report a Breach' button anchored top-right, high-contrast red, isolated from routine dashboard content.
The final "Report a Breach" widget effectively solves the crisis paradox. By leveraging strict right-alignment and emergency color contrast in a premium top-row location, the widget remains instantly readable and highly accessible when a customer is under attack, without aggressively shouting over the daily self-serve tools below it.
A Unified Experience
When you pull back and look at the final dashboard, the spatial layout really pays off. The goal was never just to make the legacy dashboard "look better" it was about giving enterprise customers a place to actually work and manage their security posture autonomously. Ultimately, we took a fragmented legacy interface and transformed it into a cohesive, production-ready product using our internal design system.
The final IR Dashboard Overview + Work Area layout combining the top row summary with the full self-serve workspace below.
The Business & User Impact
The launch of the Incident360 Retainer was a massive commercial success, driving immense sales and receiving overwhelmingly positive feedback from customers who loved the new self-serve capabilities.
$9M Revenue Growth in 12 Months
Following its launch in May 2025, the premium retainer tiers (Incident360 and Incident360 Plus with the Rapid Response Add-On, excluding the entry-level JumpStart tier) scaled rapidly from $0 to $9 million in generated revenue.
Independent Industry Validation
The product received highly visible industry recognition in a July 2025 IDC Market Note titled, "Arctic Wolf's Incident Response Retainer Plan: Why Didn't Anyone Think of This Before?"
Validated UX Strategy
The IDC report explicitly highlighted the newly designed IR Dashboard, noting that it "provides tools for incident response planning, cyber-resilience assessment, and insurability evaluation."
Proven Efficiency
By centralizing these complex workflows into an intuitive self-serve portal, the dashboard successfully achieved its core goal of "enhancing preparedness and response efficiency" for midmarket organizations.
Reflections as a Lead Designer
Protecting the Scope
Moving fast in enterprise B2B requires ruthless prioritization. Aligning closely with engineering from day one gave me the confidence to cut unscalable features like the real-time pizza tracker. Pushing back on scope ensured we hit our aggressive 3-month target with a rock-solid, reliable product.
Designing for the Worst-Case Scenario
Designing for an active cyber breach reinforced that sometimes the most effective UX is the quietest. When a user is in a state of panic, extreme visual restraint and spatial clarity are far more critical than flashy interactions.